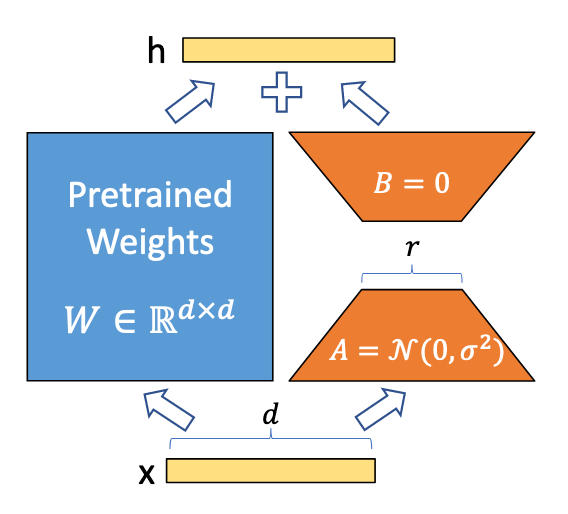
ICLR 2022 (Poster). [Paper] [Page] [Github]Edward Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu ChenMicrosoft Corporation06 Oct 2021연구 주제 및 주요 기여LoRA는 Fine-tuning의 비용을 줄이고자 고안된 Adapter-based methods 중 하나이다.Fine-tuning시 기존 Dense layer의 파라미터를 변경하지 않고, r차원으로 줄였다가 다시 복원하는 Low-Rank Adaptation을 추가해 학습하도록 제안했다.이는 추론시 기존 파라미터와 병합할 수 있기 때문에 Inference Latency의 ..
논문 리뷰기존 Adapter-based 방법과 달리 layer 사이에 새로운 adapter를 추가하는 게 아닌, low-rank decomposition 행렬을 기존 파라미터와 평행하게 배치하고 LoRA 모듈만 변경되도록 해 학습 비용을 획기적으로 줄이면서도 추론시 기존 파라미터와 병합해 추가적인 inference latency가 없게 할 수 있었다.이 뿐만 아니라 low-rank decomposition으로서 학습된 를 기존의 와 비교해, Adaptation 과정에서 사전 학습에서 특별히 더 중요하진 않았지만 특정 task에서는 중요한 특징들을 학습하고 있다는 것을 보인 점이 더욱 흥미로웠다. 의문점1. Scaling factor 은 왜 필요한가?..
Generalization기존의 전통적인 프로그래밍에서는 사람이 모든 경우의 수를 고려하여 명확한 조건과 규칙을 기반으로 결과를 도출했다. 이는 규칙을 기반으로 하기에 Rule-based System이라고도 한다. 하지만 우리가 다루는 데이터가 더욱 복잡해짐에 따라, 모든 경우의 수를 반영해서 프로그래밍 하는 것은 현실적으로 불가능해졌다. 이를 해결하기 위해 수집한 데이터에 있는 특성과 패턴을 파악해서 수집한 데이터 뿐만 아니라 보지 못한 모든 데이터에서도 잘 동작하는 능력인 일반화 능력을 가진 인공지능 모델을 개발하려 하는 것이다.Underfitting and OverfittingUnderfitting은 모델의 일반화 성능을 따질 것도 없이 훈련 데이터 셋에 대해서도 잘 동작하지 않는 상태이다. 말그대..
Transformer는 시퀀스 데이터를 순차적으로 처리하는 기존의 RNN 구조를 버리고 내적을 통해 집중해야 하는 정보가 어떤 것인지 스스로 학습할 수 있게 하는 Attention Mechanism을 적극 활용한 모델이다. Positional EncodingTransformer에서는 순차적으로 처리하는 RNN과 달리 Attention을 통해 시퀀스 데이터가 한 번에 처리되기 때문에 순서에 대한 정보가 들어가지 않는다.그래서 Transformer에서는 Positional Encoding 또는 Positional Embedding을 통해 얻은 위치 임베딩 벡터를 단어 임베딩 벡터에 더해 위치 정보를 담는다. Positional Encoding은 다음의 두 공식을 통해 얻은 고정된 벡터를 사용하는 방식이다. ..